Le but de cette partie est la réalisation d’une classe StringSet
des ensembles
de chaînes qui suit (en partie) le modèle des Set<String> de la
bibliothèque de Java.
On suppose déjà écrite une classe simple des cellules de liste de chaînes.
Cette classe List sera utilisée telle quelle dans la suite
du problème, ou complétée si besoin est. Autrement dit, vous ne
pouvez pas supposer que la classe List offre des méthodes sans
les écrire vous-même.
Voici un squelette de la classe StringSet.
Chaque objet de la classe StringSet représente un ensemble géré
sur le mode destructif. Il possède en particulier un champ privé
List p qui est la liste de ses éléments, sans doublons.
Tous les corps de méthodes notés {…} ci-dessus
sont à écrire comme demandé par les questions qui suivent.
null) dont
la liste des éléments p vaut null.
Cette remarque peut sembler inutile ou évidente, elle commande que les
méthodes qui manipulent les listes sont du genre static, qui
prennent la liste en argument explicitement ;
tandis que les méthodes des StringSet sont dynamiques, puisque null
n’est pas un ensemble valide.
À l’intérieur du code de ces méthodes dynamique, this représente
l’objet dont on a appelé la méthode.
Si vous n’avez pas encore compris le truc,
jetez un œil sur par exemple
le cours 421.
Question 1. Écrire les deux premières méthodes, isEmpty
et contains.
equals.
Question 2. Écrire la méthode choose. Si l’ensemble est
vide, la méthode choose doit lancer
l’exception NoSuchElementException.
Sinon, l’appel à choose renvoie un élément, peu importe lequel,
de l’ensemble.
L’ensemble n’est pas modifié.
throw apparaissait. Qu’on se le dise : une exception
est un objet, que l’on construit comme les autres.
Question 3. Écrire la méthode add.
Soient xs, un objet StringSet, et x, une chaîne.
Si x n’est pas déjà présent dans xs, alors
l’appel xs.add(x) ajoute l’élément x à l’ensemble
xs (qui est donc modifié) et renvoie true.
Sinon, xs est inchangé, et l’appel renvoie false.
Question 4. Écrire la méthode remove qui est semblable
à add, à ceci près que l’élément est supprimé de l’ensemble.
Ici encore le booléen renvoyé traduit un changement de l’ensemble
— true si l’élément a été effectivement supprimé,
false sinon.
p de l’objet StringSet
(i.e this.p).
Dans tous les autres cas, on modifie le champ next
d’une cellule de liste.
Une solution récursive est un peu plus simple.
Certes il y a jusqu’à deux parcours de liste, mais la complexité est identique (linéaire en la longueur de la liste).
removeList non
destructive, c’est juste un peu plus coûteux, à cause des allocations
de cellules de liste.
Question 5. Majorer le mieux possible l’ordre de grandeur asymptotique
(notation O) des opérations élémentaires sur les ensembles,
contains, add et remove, en fonction du cardinal de
l’ensemble. Quelle autre structure de données que la liste pourriez
vous utiliser pour améliorer ces coûts ?
p.
Elles sont donc en O(n).Si à la place de la liste p on emploie un arbre binaire
de recherche
équilibré (AVL par exemple), alors les coûts se réduisent
en O(log(n)).
Avec une table de hachage, on obtient des coûts réputés en temps
constant — sous réserve de hachage uniforme et de table bien dimensionnée.
Question 6. Écrire la méthode iterator, cette méthode renvoie
un objet qui implémente l’interface
Iterator<String>.
L’interface générique Iterator<E> est fournie par la
bibliothèque de Java, en voici une version simplifiée.
L’objet renvoyé par iterator() possède donc les
méthodes public boolean hasNext()
et public String next(), qui servent à parcourir les
éléments de l’ensemble. La première méthode teste si le parcours est
terminé, tandis que la seconde renvoie un élément et avance le
parcours d’un cran. La combinaison de ces deux méthodes permet de
parcourir tous les éléments d’un ensemble, pour par exemple les
afficher.
current ci-dessous)
sur la liste des
éléments, référence qui progresse à chaque appel à next().
iterator d’un objet StringSet se contente
de renvoyer un nouvel objet StringSetIterator,
initialisé au début de sa liste privée p.
Iterator<E>.
En effet, la documentation de Java précise deux contraintes
supplémentaires.
next()
lance l’exception NoSuchElementException. On aurait pu donc écrire.
null, dès sa première ligne r = current.val.remove()
à la sémantique particulièrement tordue (enlever l’élément
rendu par un appel à next() qui vient d’avoir lieu).
Toutefois, le concepteur de
l’itérateur peut ne pas fournir ce service, auquel cas sa méthode
remove lève l’exception UnsupportedOperationException.
Notre classe StringSet implémente
l’interface Iterable<String>.
Cela autorise une écriture simplifiée des parcours d’ensemble.
Par exemple, l’affichage d’un ensemble peut aussi s’écrire ainsi :
On ne se privera pas d’employer l’écriture simplifiée dans la suite du problème.
Les divers logiciels que l’on peut installer sur une machine sont définis comme des paquets. Un paquet est concrètement un regroupement de programmes, de bibliothèques, etc.
Pour fonctionner correctement les paquets ont la plupart du temps besoin d’exécuter d’autres paquets. On dit alors qu’un paquet dépend pour son exécution d’un autre. Par exemple, le compilateur Java (paquet sun-java5-jdk) est un programme Java. Son exécution entraîne directement l’exécution de la machine virtuelle Java (paquet sun-java-bin) et le compilateur peut directement faire appel aux méthodes de la bibliothèque Java (paquet sun-java-jre).
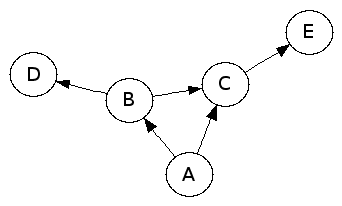
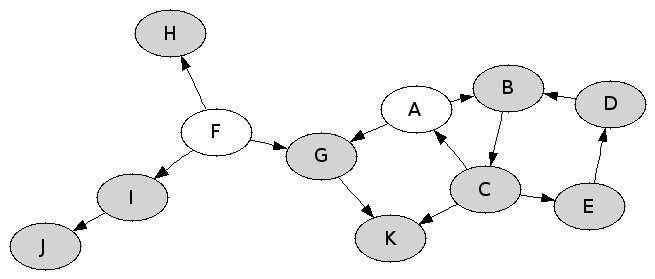
L’ensemble des dépendances entre paquets est idéalement représenté par un graphe orienté, dit graphe des dépendances. Les sommets du graphe sont les noms des paquets et les arcs traduisent les dépendances pour l’exécution. Par exemple :
Il est important de comprendre que pour exécuter le paquet A, on a besoin de tous les paquets de A à E. En effet, non seulement, A dépend de B et de C. Mais aussi, B et C dépendent de D et de E respectivement.
Les paquets peuvent être installés sur la machine ou pas. Dans les dessins, les paquets installés sont grisés. Voici deux états de machine.
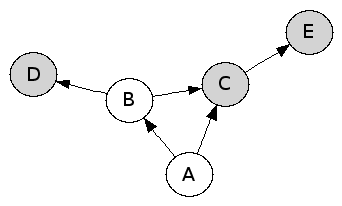
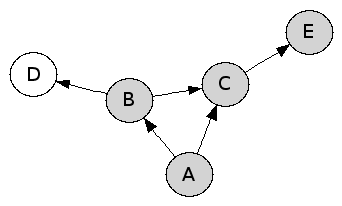
Un paquet est exécutable, quand il est installé et que tous les paquets dont il besoin pour s’exécuter sont installés. Un état de la machine est cohérent quand tous les paquets installés sont exécutables. Dans l’exemple de gauche, l’état de la machine est cohérent. En revanche, l’état de droite n’est pas cohérent, car les paquets B et A ne sont pas exécutables — le paquet B directement, et le paquet A indirectement.
Il faut noter que les dépendances circulaires ne posent pas de problème.
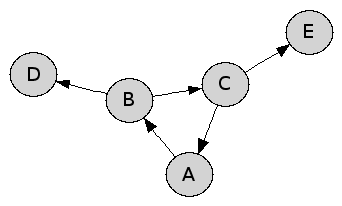
Ici, tous les paquets sont installés et tous sont exécutables.
Question 7. Donner tous les paquets exécutables de l’état suivant. Cet état est-il cohérent ?
Nous représentons en Java l’état d’une machine par la classe Mach.
Le graphe des dépendances est représenté par la méthode
dependsRun ci-dessus, qui prend un nom de paquet pack
en argument et renvoie l’ensemble (StringSet) des paquets dont
pack dépend pour son exécution.
La méthode dependsRun est donnée, vous n’avez pas à l’écrire.
Toutes les méthodes demandées par la suite sont des méthodes statiques de la
classe Mach.
Question 8. Écrire une méthode
static StringSet neededToRun(String pack)
qui renvoie l’ensemble des paquets dont
pack a besoin pour s’exécuter.
Majorer le nombre d’opérations add effectuées, pour
un graphe comportant n sommets et m arcs.
work.add est effectué au plus n fois,
car un sommet donné n’est ajouté à work qu’au plus une fois
(grâce à l’ensemble needed qui fait office d’ensemble des
sommets vus).L’appel needed.add est effectué au plus 1+m fois.
On a d’une part l’appel initial, et d’autre part
un appel par arc rencontré. Or les sources des arcs rencontrés sont
deux à deux distinctes (cf. ci-dessus).
Ou aurait pu remplacer l’ensemble work par une pile, une file, etc.
On serait alors un peu plus efficace, car lors de l’ajout de d à
work, nous sommes sûrs que d n’appartient pas à work.
pack fait partie
de l’ensemble des paquets dont pack a besoin pour s’exécuter.
On peut aussi écrire un parcours dfs récursif, par exemple.
Clairement, il y a un appel à needed.add par appel à dfs,
et effectuer un appel récursif à dfs revient à suivre un arc du
graphe.
Or, chaque arc est suivi
au plus une fois, car les sources des arcs suivis sont
deux à deux distinctes (add ne peut répondre true deux
fois pour un même paquet ajouté).
Il y a donc au plus m appels récursifs de dfs, plus un appel
initial.
Soit finalement, au plus m+1 appels à needed.add.
Question 9. Écrire deux méthodes.
a)
La méthode static StringSet missingPackages(String pack)
renvoie l’ensemble des paquets dont pack a besoin pour s’exécuter
et qui ne sont pas déjà installés.
pack a besoin pour s’exécuter.
Compte tenu de ce que nous savons de l’implémentation
de StringSet il est plus que raisonnable de fabriquer un nouvel
ensemble, au lieu d’enlever les éléments de needed ci-dessous
à l’aide de sa méthode remove.
b)
La méthode static boolean canRun(String pack)
détermine si pack est exécutable ou pas.
missingPackages(pack) == null à la place de l’appel à
isEmpty(). Cela coûte tous les points.
L’utilisateur de la machine peut souhaiter installer de nouveaux
paquets. Il est logique de n’installer que des paquets exécutables,
et le système d’exploitation s’efforce de conserver la machine dans un
état cohérent. Plus précisément, quand l’utilisateur demande
d’installer un paquet a, le système d’exploitation de la machine
décide d’installer tous les paquets de l’ensemble
missingPackages(a).
On dit alors que le système d’exploitation installe le paquet a
complètement.
Mais les choses ne sont pas si simples. L’installation d’un paquet a se décompose en deux étapes : d’abord obtention du paquet a (téléchargement, CD-ROM, etc.) ; puis installation proprement dite de a (copie des fichiers à leur place définitive, configuration, etc.). Il peut se faire que cette dernière procédure exécute un autre paquet b. En ce cas, nous dirons que le paquet a dépend pour son installation du paquet b. Si a dépend pour son installation de b et que b n’est pas exécutable, alors l’installation de a échoue. Nous notons a → b (flèche ordinaire) une dépendance d’exécution et a ➜ b (flèche en gras) une dépendance d’installation Le graphe des dépendances comprend donc désormais deux sortes d’arcs. On aura par exemple :
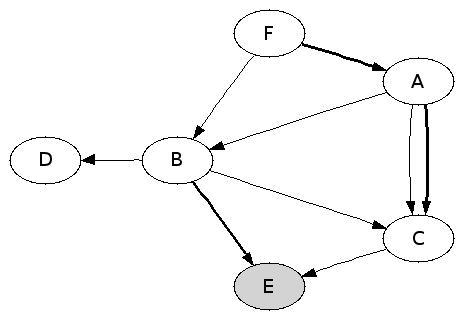
Question 10. La machine est dans l’état décrit juste ci-dessus. En réponse à une demande d’installation de F, le système d’exploitation décide d’installer A, B, C, D et F, dans cet ordre. Identifier un problème et y remédier.
On peut réussir à installer complètement F en installant les paquets dans l’ordre, C, B, D, A et puis F. Plus généralement, est correct tout ordre qui installe C avant A et installe complètement A avant F.
Question 11. Nous notons I l’ensemble des paquets installés, que nous supposons cohérent. Nous notons a ⇒ b, lorsque a → b, ou a ➜ b, ou les deux. Nous notons ⇒* la fermeture réflexive et transitive de ⇒ — a ⇒* b signifie qu’il existe un chemin (éventuellement vide) de a vers b.
Pour tout paquet a non-installé, nous définissons l’ensemble d’arcs
| Dep(a,I) = { b ⇒ c ∣ c ∉I, a ⇒* b ⇒ c}. |
L’ensemble Dep(a, I) est assimilable à un sous-graphe du graphe des dépendances, limité aux paquets non-encore installés et nécessaires pour installer et exécuter a. Par cohérence de I, le graphe Dep(a,I) est connexe.
Une copie fait remarquer que Dep(a,I) n’est pas toujours connexe pour une machine cohérente. La remarque est (malheureusement pour nous) juste
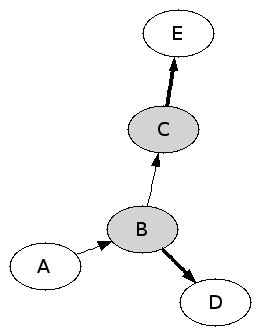
Ici I = { B, C } et Dep(A,I) = { B ➜ D, C ➜ E }. Cela correspond à la situation où B et C ont été installés proprement (en installant également D et E), et où D et E ont été ensuite effacés. Cette petite erreur d’énoncé est en fait un détail. La correction la plus simple (que presque tous ont adoptée inconsciemment) est de prendre la connexité comme hypothèse supplémentaire. Cette hypothèse est valide quand l’installation des paquets est commencée sur une machine vide et qu’aucun paquet n’est effacé.
Au fond l’hypothèse de cohérence est la suivante : si a est installé, alors tous les sommets atteignables à partir de a par → sont installés. La suite sans heurts du problème demande de considérer que la propriété est vraie également pour ⇒.
Nous définissons également Δ(a, I), l’ensemble des sommets du sous-graphe Dep(a, I).
| Δ(a, I) = { b ∣ ∃ c ⇒ b ∈ Dep(a, I) } ⋃ { a } |
a)
On suppose que Dep(a,I)
contient un cycle de la forme
b ➜ c ⇒* b.
Expliquer pourquoi l’installation complète de a est
impossible dans ces conditions.
b)
On suppose qu’il n’existe pas
de cycle b ➜ c ⇒* b dans
Dep(a,I). Montrer qu’il existe alors un paquet d de
Δ(a, I) qui est tel que Dep(d,I) ne contient pas
d’arc ➜.
On demande un algorithme exprimé en pseudo-code qui étant donné a
calcule d.
On peut se demander de façon plus générale à quel niveau de détail il faut descendre dans le pseudo-code. Disons que ce qu’il y a ci-dessus est du bon niveau de détail, pour cette question, car :
missingPackages de la question 9).
c)
En déduire un algorithme qui installe a complètement et sans échec,
dans le cas précité où il n’existe pas
de cycle b ➜ c ⇒* b dans
Dep(a,I).
On peut ensuite installer tous les paquets de Δ(a,I) ainsi.
Où les affectations de I expriment les installations effectives. Les installations effectuées ne peuvent pas échouer (cf. ci-dessus). L’algorithme termine, car Δ(a,I) décroît strictement à chaque tour de boucle (d au moins est installé).
choose les uns
après les autres. Il convient d’être précis, en donnant par exemple le pseudo-code :
Bon on peut se dire que choose peut être plus malin, et c’est
l’objet de la question suivante.
Les dépendances pour l’installation
sont représentées en machine par une nouvelle
méthode statique dependsInstall de la classe Mach.
L’installation effective d’un paquet est réalisée par la méthode install.
Ici encore,
la méthode dependsInstall est donnée, vous n’avez pas
à l’écrire.
La méthode install est également donnée, son code traduit
en Java ce que l’énoncé entend par l’échec de l’installation
d’un paquet.
Question 12. Écrire une méthode static void safeInstall(String pack) qui installe
pack complètement si c’est possible, ou sinon provoque une erreur.
Par ailleurs, safeInstall doit être aussi efficace que possible,
c’est-à-dire effectuer au plus un parcours du graphe des dépendances.
Aucune preuve de correction n’est demandée.
s n’est pas exécutable lors de l’exécution
de install(p). En raison des propriétés du parcours en
profondeur, cet évènement survient
p ➜ s est un arc
de retour.
p ➜ s est un arc de l’arbre de
recouvrement, et que Dep(s,I) contient un arc de retour
pointant sur un ancêtre de p au sens large.
seen conduit à
revenir de topo sans que le paquet cible de l’arc de retour soit
installé. Ce qui conduit plus tard à un erreur lors de la tenative
d’installation de p. Ce qui n’invalide pas la correction de
safeInstall, puisque dans les deux cas, il existe un cycle qui
interdit l’installation de p.p dès que les paquets dont
son installation dépend sont exécutables est également
valable.
p soit exécutable à la
fin de la méthode topo (disons en l’absence de cycles, pour simplifier).
This document was translated from LATEX by HEVEA.